1. 容灾定义
容灾 (Disaster Recovery),即容灾备份或灾备,是业务连续性系统的一个子集,用于保障 IT 系统在遭受自然灾害、人为操作失误或蓄意破坏后的数据还原和业务恢复[1][2]。
2. 容灾意义
在当前信息社会的大环境下,信息全面电子化,数据高度集中,然而自然灾害无处不在,人为失误或破坏难以杜绝,所导致的业务中断、数据丢失对银行、企业、政务等影响重大,因此灾备建设关系重大非常重要。
3. 容灾方案
业务连续性容灾解决方案一般包括四个子方案:本地高可用解决方案、主备容灾解决方案、双活容灾解决方案和两地三中心解决方案[3],应用场景如图1所示:
![图1 业务连续性容灾解决方案应用场景[4]](dc.png)
其中两地三中心,特别是同城双活+异地灾备方案,由于具有更高的业务连续性保障,逐步成为银行、政务、大型企业等数据中心解决方案的基本要求[5][6][7]。
两地三中心(同城双活+异地灾备)方案的总体架构如图2所示:
![图2 两地三中心总体架构[5]](arch.png)
在同城范围,即 30 至 100 公里以内使用裸光纤实现两个生产中心之间的互连,并使用CWDM/DWDM波分复用方案来提高中心之间的带宽和可用性[8]。两个数据中心间数据进行同步复制,业务通过负载均衡等技术进行跨中心接入。日常运行时,两个数据中心都处于运行状态,运行相同业务,数据实时一致。当单数据中心灾难时,另一个数据中心可以接管所有业务,业务可快速恢复,数据零丢失。异地数据中心作为备用中心,数据从同城生产中心异步复制到远程灾备中心,当同城两个数据中心均发生灾难时,业务全部切换到异地数据中心,数据可能存在少量丢失。
4. 数据容灾
数据容灾是 IT 系统容灾的基础,数据容灾方案必须能够实现对数据库数据、文件存储、块存储、对象存储、SAN 阵列等进行实时有效的保护[9]。
5. Ceph容灾
Ceph 作为开源存储系统,能同时对外提供文件、块、对象三种接口,由于它能够构建在普通的 x86 服务器上,相对廉价且具有非常好的横向扩展性,在数据中心云化/虚拟化的大环境下[10],特别是 OpenStack 云环境中,Ceph 占据了越来越多的存储份额。
如图3所示,Ceph 在系统架构上可以分为两层,底层 RADOS 存储层和上层应用(即文件、块、对象)访问层,其中 RADOS 层为上层应用接口提供了私有的存储访问接口(librados)[11],因此 Ceph 的容灾也可以从 RADOS 和应用两个层面分别进行考虑。
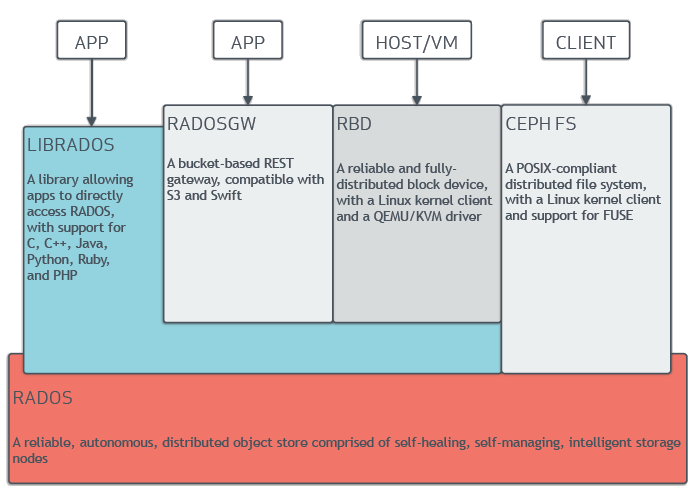
5.1 RADOS 层容灾
RADOS 层支持多副本和 EC (实验性质) 两种形式的数据冗余机制,数据依据 CRUSH 伪随机算法[12]在用户定义的多个故障域(如DC、room、rack、host等)内分散分布,因此在设计上 RADOS 层实际上就已经具备了一定的容灾能力,在合理的 CRUSH 规则和冗余策略配置下,单个磁盘、节点甚至数据中心的丢失并不会导致数据丢失,集群能够自愈或在降级状态下工作。
但是 RADOS 层的容灾需要考虑两个问题:1)RADOS 层的数据写入要求强一致性,因此数据跨域,特别是跨数据中心分布对域间的带宽和时延[13]有严格要求(注:需相关性能数据支撑);2)无法抵御人为操作失误或蓄意破坏。由于带宽和时延的要求 RADOS 层一般仅适用于单个 Ceph 存储集群支持两地三中心部署模式下的同城双活或多活业务中心,而为了抵御人为因素导致的数据破坏或丢失,则需要依赖于上一层的应用接口甚至上层业务的直接支持。
注:可能与容灾无关,但当数据跨中心时,特别是云环境下虚机跨数据中心迁移,要求 Ceph 存储考虑跨数据中心的大二层网络连通性[14][15]。
5.2 应用层容灾
如前文所述,RADOS 层的数据冗余及跨域分布机制并不是一个完整的 Ceph存储容灾解决方案,因此 Ceph 在 RADOS 层之上针对文件 (CephFS)、块 (RBD) 以及对象 (RGW) 三种存储应用还提供了一些辅助的高可用、数据备份恢复功能。
CephFS 自身的在 Jewel 版本才达到生产环境使用要求,因此在容灾方面的考虑暂时并不多,当前只有快照功能[16],在文件备份恢复方面并无更多的支持。
RBD 支持常见的快照导入、导出,以及增量快照导入、导出,而且为了支持块设备多集群分布,在 Jewel 版本还引入了 RBD mirroring 功能[17],在块设备备份恢复方面有较好的支持(可参考:Ceph RBD块设备容灾备份)。
RGW 在 Jewel 版本中提供了 multisite 功能[18] 用以支持多数据中心多活,但在对象的备份恢复方面也无更多的支持。
在存储之上的业务层,特别是 OpenStack 对接 Ceph 存储后端的场景下,当前有一些实验性质的方案[19][20][21][22],但并无成熟的解决方案,总的来说任重而道远。
6. 参考资料
[1] Disaster recovery
https://en.wikipedia.org/wiki/Disaster_recovery
[2] How to write a disaster recovery plan and define disaster recovery strategies
[3] 业务连续性容灾解决方案
http://e.huawei.com/cn/solutions/business-needs/data-center/datacenter/disaster-recovery
[4] 华为业务连续性灾备解决方案彩页
[5]
[6]
http://www.wavetop.com.cn/about/news/702.html
[7] 华为业务再次从深圳外迁 数据中心转移至东莞
http://www.cnbeta.com/articles/571071.htm
[8]
http://www.cisco.com/web/CN/newsletter/2013/03/files/double_datacenter_solutions.pdf
[9] 容灾备份解决方案
http://www.sansky.net/article/2007-08-18-disaster-recovery-backup-solution.html
[10]
[11] Ceph ARCHITECTURE
http://docs.ceph.com/docs/master/architecture/
[12] CRUSH: Controlled, Scalable, Decentralized Placement of Replicated Data
https://ceph.com/wp-content/uploads/2016/08/weil-crush-sc06.pdf
[13] Understanding the Difference between Bandwidth and Latency
https://learningnetwork.cisco.com/docs/DOC-20320
[14] 云网络的宏大未来:大二层网络
http://bengo.blog.51cto.com/4504843/795619
[15] Virtual Extensible LAN
https://en.wikipedia.org/wiki/Virtual_Extensible_LAN
[16] CEPHFS SNAPSHOTS
http://docs.ceph.com/docs/master/dev/cephfs-snapshots/
[17] RBD MIRRORING
http://docs.ceph.com/docs/master/rbd/rbd-mirroring/
[18] MULTI-SITE
http://docs.ceph.com/docs/master/radosgw/multisite/
[19] Cinder’s Ceph Replication Sneak peek
https://gorka.eguileor.com/ceph-replication/
[20] OpenStack Docs: Cheesecake
https://specs.openstack.org/openstack/cinder-specs/specs/mitaka/cheesecake.html
[21] CephFS as a service with OpenStack Manila
http://events.linuxfoundation.org/sites/events/files/slides/CephFS-Manila-0.2_0.pdf
[22] Freezer-backup-restore
https://wiki.openstack.org/wiki/Freezer-backup-restore
最后修改于 2019-01-04