Ceph 作为一个开源存储项目,是 OpenStack 生态中软件定义存储领域的一个重要参与者,由于其分布式统一存储的本质,得到了越来越多 IaaS、PaaS 厂商的重视。
在实际生产系统中,容灾备份是基本的功能需求,Ceph RBD 作为块设备存储后端,当前并未提供完整的解决方案,但提供了必要的辅助设施,下文分别从容灾和备份两个方面分别进行介绍。
容灾 (Disaster Recovery)
RBD mirroring 是 Ceph Jewel 版本的新增功能[1],用于为 RBD image 提供块设备级 (Crash Consistency)[2] 的容灾能力。
基本原理
RBD mirroring 类似于传统存储设备提供的异步复制功能,客户端的数据只需要写本地块设备即可应答返回,异步写入远端块设备的操作由独立的远程镜像模块进行。
启用 RBD mirroring 功能需要满足以下几个必要条件:
- image 支持两个新特性:exclusive-lock、journaling;
- image 使能 mirroring 配置;
- 独立的 rbd-mirror 守护进程进行数据同步。
但需要注意的是由于内核态 RBD 客户端的开发远远滞后于用户态 librbd 的开发,因此一旦开启新特性将使得该 image 无法被内核态的 RBD 客户端访问,同时还要注意的是 RBD mirroring 不是传统意义上的备份操作,当本地集群由于误操作等原因导致 image 被删除,rbd-mirror 会在远端集群应用同样的删除操作。
exclusive-lock
用于协调 RBD image 读写访问的分布式锁,通过该锁可以控制 image 只能被独占访问,当 RBD 客户端(如 qemu)打开 image 进行读写时,需要先拿到该锁,并且会在 image 内部记录客户端所归属的集群,从而区分 image 的主备角色。
journaling
RBD 客户端的写操作(如 write/discard,包括完整的数据)以及管理操作(如创建快照),会记录在一组日志对象中,然后再应用到后端 image 中,最后才会给客户端应答,因此相比未启用 journaling 的情况下,客户端读写操作的时延会有明显增加。
rbd-mirror
rbd-mirror 是一个守护进程,同时连接至两个集群的业务网络 (public network),如下图所示,它通过定时器驱动读取远端集群image 的日志,然后在本地集群应用 (replay) 相应的操作,从而实现在本地集群完整复制远端集群的 image 的功能。
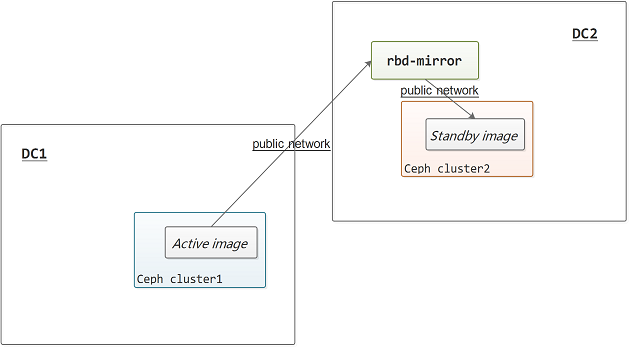
如果需要实现 failback,则rbd-mirror 需要同时在两个集群进行部署,当 image 进行主备切换时,rbd-mirror 总会将远端集群中的主 image 同步到本地集群中的备 image。
灾难恢复
如前所述,通过 image 内部的记录能够区分主备角色,当主 image 所在的集群发生故障,或者需要进行负载迁移时,可以将主 image 进行降级 (demote) 操作,然后将备 image 提升 (promote) 为主 image,如果原集群已经无法访问,则可以将备 image 进行强制提升,但需要注意的是由于 RBD mirroring 是通过异步复制的方式实现的,如果不将原来的主 image 降级并等待数据同步完成而直接强制提升备 image,则可能会存在数据丢失的风险。
RBD mirroring 并不提供自动化的 failover/failback 支持,必须由上层应用(如 Cinder、Glance)或管理员来进行相关的决策。
操作实践
略。
备份 (Backup)
RBD image 备份及增量备份都是基于其提供的快照 (snapshot) 导出 (export)、导入 (import) 功能,在 Ceph 早期版本中就已经提供了相关的支持[4][5]。
基本原理
通过创建 image 的快照,并将快照导出,再导入到另一个 Ceph 集群或者转移到其它存储设备中,可以实现 image 的备份功能。RBD image 支持全量和增量两种形式的导出、导入,支持导出至文件或标准输出流,支持从文件或标准输入流中导入。
快照
RBD image 在 RADOS 层中以一组对象的形式存在,其快照实现也依赖于 RADOS 层对象的写时复制 (COW) 机制。image 的快照创建操作并不会带来任何的数据 IO,但在下一次客户端 IO 发起前,image 的客户端会更新自己的快照上下文,针对 RADOS 层对象的修改操作会根据该快照上下文信息判断是否需要进行对象的复制操作,从而实现 image 层的 COW。
rbd export/import
全量形式的导出、导入不需要快照支持,全量导出通过线性扫描整个 image 将 image 的数据读出并写入文件/标准输出流,全量导入则通过新建 image 并将文件/标准输入流中的数据写入 image 来实现。但这种形式的操作会存在应用数据不一致的情况,因此,全量形式的导出、导入操作的终结点应当是快照。
rbd export-diff/import-diff
增量形式的导出、导入需要快照支持,通过线性扫描 image 与上一个快照之间有修改的 image 数据并写入文件/标准输出流,增量导入则基于已有的快照从文件/标准输入流中导入新增修改并写入 image。与全量形式的操作类似,增量数据如果是直接基于当前 image 与上一个快照的增量,则同样会存在应用数据一致性问题,因此,实际操作中的起始点和终止点都应当是快照。
备份恢复
当进行全量备份恢复时,如果原 image 已经不存在,则直接导入备份的 image 即可,如果原 image 已存在,则需要删除原 image 再导入备份的 image。而当进行增量备份恢复时,需要确保基准快照存在,增量备份数据导入完成之后,会自动新建后一个基准点的快照。
操作实践
略。
总结
当前 Ceph 提供了一些基础的工具、功能用于容灾备份,但具体的调度需要上层的系统进行统一处理。另外由于 RBD mirroring 是新增功能,当前还未经过大规模的验证,而且当前也并未实现守护进程自身的横向扩展及 HA[5],因此在大规模使用场景下 rbd-mirror 自身及所在机器的网卡可能会成为瓶颈。OpenStack 与 Ceph 结合的容灾备份方案还有很长的路要走[6]。
参考文献
[1] Ceph Jewel Preview: Ceph RBD mirroring
http://www.sebastien-han.fr/blog/2016/03/28/ceph-jewel-preview-ceph-rbd-mirroring/
[2] RBD mirroring design draft
http://www.spinics.net/lists/ceph-devel/msg24169.html
[3] INCREMENTAL SNAPSHOTS WITH RBD
http://ceph.com/dev-notes/incremental-snapshots-with-rbd/
[4] RBD Replication
http://cephnotes.ksperis.com/blog/2014/08/12/rbd-replication
[5] RBD Mirror Horizontal Scale-out
http://pad.ceph.com/p/rbd_mirror_scale
[6] Protecting the Galaxy - Multi-Region Disaster Recovery with OpenStack and Ceph
最后修改于 2019-01-03