Python 源代码的执行流程大概如下图所示:
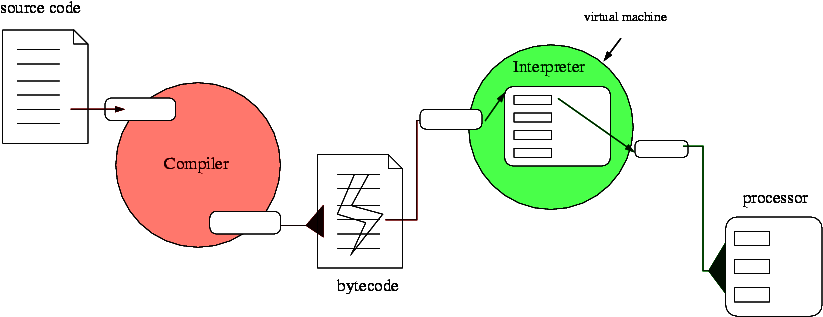
源代码被转换(编译)成字节码(bytecode),然后在 Python 解释器上下文对字节码进行解释执行。
pyc
通过 py_compile 模块可以将 Python 源文件编译成 pyc 格式的文件,实际上就是 Python 解释器可加载的字节码二进制文件格式(类似于 Java 的 class 文件)。
$ ls
add.py
$ python2.7 -m py_compile add.py
$ ls
add.py add.pyc
$ python3.5 -m py_compile add.py
$ python3.6 -m py_compile add.py
$ python3.7 -m py_compile add.py
$ ls
add.py add.pyc __pycache__
$ ls __pycache__/
add.cpython-35.pyc add.cpython-36.pyc add.cpython-37.pyc
pyc 文件的格式随着 Python 版本的变化可能变化,因此解析时需要根据文件头中前四个字节所标示的 magic 值进行判断:
Python < 3.3 pyc 文件头只有 magic 和 timestamp(源文件修改时间)两个字段;
Python >= 3.3 pyc 文件头在 timestamp 之后新增了 size(源文件字节数)字段;
Python >= 3.7 pyc 文件头在 magic 之后新增了 hash(源文件 hash 标示)字段;
注意 hash 只是一个 flag 字段,当该字段不为 0 时,则改变 timestamp 字段的用途为源文件的哈希值(PEP 552)。
一个简单的解析 pyc 文件的脚本如下(参考了 Ned Batchelder, Eric Snow 及 amedama 的代码):
import binascii
import dis
import marshal
import struct
import sys
import time
import types
try:
from StringIO import StringIO
except ImportError:
from io import StringIO
INDENT = ' ' * 4
MAX_HEX_LEN = 16
NAME_OFFSET = 20
def hexdump(bytes_value, level=0, wrap=True):
indent = INDENT * level
line = ' '.join(('%02x',) * MAX_HEX_LEN)
last = ' '.join(('%02x',) * (len(bytes_value) % MAX_HEX_LEN))
lines = (line,) * (len(bytes_value) // MAX_HEX_LEN)
if last:
lines += (last,)
if wrap:
template = indent + ('\n' + indent).join(lines)
else:
template = ' '.join(lines)
try:
return template % tuple(bytes_value)
except TypeError:
return template % tuple(ord(char) for char in bytes_value)
def show_consts(consts, level=0):
indent = INDENT * level
i = 0
for const in consts:
if isinstance(const, types.CodeType):
print('%s%s (code object)' % (indent, i))
show_code(const, level=level+1)
else:
print('%s%s %r' % (indent, i, const))
i += 1
def show_bytecode(code, level=0):
indent = INDENT * level
print(hexdump(code.co_code, level, wrap=True))
print('%sdisassembled:' % indent)
buffer = StringIO()
sys.stdout = buffer
dis.disassemble(code)
sys.stdout = sys.__stdout__
print(indent + buffer.getvalue().replace('\n', '\n'+indent))
def show_code(code, level=0):
indent = INDENT * level
for name in dir(code):
if not name.startswith('co_'):
continue
if name in ('co_code', 'co_consts'):
continue
value = getattr(code, name)
if isinstance(value, str):
value = repr(value)
elif name == 'co_flags':
value = '0x%05x' % value
elif name == 'co_lnotab':
value = '0x(%s)' % hexdump(value)
print('%s%s%s' % (indent, (name + ':').ljust(NAME_OFFSET), value))
print('%sco_consts' % indent)
show_consts(code.co_consts, level=level+1)
print('%sco_code' % indent)
show_bytecode(code, level=level+1)
def show_file(fname):
def next_state(curr):
if curr == 'init':
return 'try_size'
if curr == 'try_size':
return 'try_hash'
return 'error'
with open(fname, 'rb') as f:
code = None
state = 'init'
while state != 'done':
magic = f.read(4)
timestamp = None
size = None
if state == 'init':
raw_timestamp = f.read(4)
timestamp = time.asctime(time.localtime(struct.unpack('=L', raw_timestamp)[0]))
if state == 'try_size':
raw_timestamp = f.read(4)
timestamp = time.asctime(time.localtime(struct.unpack('=L', raw_timestamp)[0]))
raw_size = f.read(4)
size = struct.unpack('=L', raw_size)[0]
if state == 'try_hash':
hashf = struct.unpack('=L', f.read(4))
raw_timestamp = f.read(4)
if not hashf:
timestamp = time.asctime(time.localtime(struct.unpack('=L', raw_timestamp)[0]))
raw_size = f.read(4)
size = struct.unpack('=L', raw_size)[0]
try:
code = marshal.loads(f.read())
if not isinstance(code, types.CodeType):
f.seek(0, 0)
state = next_state(state)
if state == 'error':
raise Exception('Could not parse pyc file')
continue
except ValueError:
f.seek(0, 0)
state = next_state(state)
if state == 'error':
raise
continue
except:
raise
print('magic %s' % (binascii.hexlify(magic)))
if timestamp:
print('timestamp %s (%s)' % (binascii.hexlify(raw_timestamp), timestamp))
if size:
print('size %s (%s)' % (binascii.hexlify(raw_size), size))
state = 'done'
print('code')
show_code(code)
if __name__ == '__main__':
if len(sys.argv) == 2:
show_file(sys.argv[1])
需要注意的是,在这个脚本的第一行并没有加上 bash shebang,即 #! /usr/bin/python 的字样,这是因为解析 Python2 的 pyc 文件需要使用 Python2 解释器,而解析 Python3 的 pyc 文件需要使用 Python3 解释器(因为不同版本的内置 marshal 模块对 code 对象不兼容)。
脚本输出中的 co_names, co_consts 等字段的含义可以参考 Python The standard type hierarchy Internal types 一节。
bytecode
上面提到 pyc 是 Python 字节码的二进制文件格式,我们可以使用 dis) 模块直接观察字节码:
$ python3 -m dis add.py
1 0 LOAD_CONST 0 (<code object add at 0x555f9b86dab0, file "add.py", line 1>)
2 LOAD_CONST 1 ('add')
4 MAKE_FUNCTION 0
6 STORE_NAME 0 (add)
4 8 LOAD_CONST 2 (1)
10 STORE_NAME 1 (a)
5 12 LOAD_CONST 3 (2)
14 STORE_NAME 2 (b)
6 16 LOAD_NAME 0 (add)
18 LOAD_NAME 1 (a)
20 LOAD_NAME 2 (b)
22 LOAD_CONST 4 (3)
24 CALL_FUNCTION 3
26 STORE_NAME 3 (sum)
7 28 LOAD_NAME 4 (print)
30 LOAD_NAME 3 (sum)
32 CALL_FUNCTION 1
34 POP_TOP
36 LOAD_CONST 5 (None)
38 RETURN_VALUE
Disassembly of <code object add at 0x555f9b86dab0, file "add.py", line 1>:
2 0 LOAD_FAST 0 (a)
2 LOAD_FAST 1 (b)
4 BINARY_ADD
6 LOAD_FAST 2 (c)
8 BINARY_ADD
10 RETURN_VALUE
其中第一列为源代码所在行号,第二列为指令在字节码中的偏移(即上面脚本输出中的 co_code 字段),第三列为指令名,第四列对于 LOAD_CONST, LOAD_NAME, LOAD_GLOBAL 等指令为指令参数在 co_consts, co_names tuple 中的索引,对于 CALL_FUNCTION 指令则表示需要从数据栈(evaluation stack)取指定个数的参数(具体的指令及其参数可以参考 Python Bytecode Instructions),第五列为第四列索引所对应的名字(如果有的话),结合 pyc 文件的解析,从源代码到字节码的转换应该是比较容易理解的。
指令及其二进制表示可以通过如下方式进行查看:
>>> import dis
>>> dis.opmap['LOAD_CONST']
100
>>> dis.opname[100]
'LOAD_CONST'
>>> dis.opname[0x7c]
'LOAD_FAST'
除了通过 py_compile 模块直接生成 pyc 文件,然后通过 dis 模块解析来分析字节码之外,还可以在 Python 的交互终端中进行实验:
>>> import dis
>>> g = 3
>>> def x(a, b):
... global g
... a += 1
... b += 2
... g += 3
... return a + b + g
...
>>> dir(x.__code__)
['__class__', '__cmp__', '__delattr__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__gt__', '__hash__', '__init__', '__le__', '__lt__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', 'co_argcount', 'co_cellvars', 'co_code', 'co_consts', 'co_filename', 'co_firstlineno', 'co_flags', 'co_freevars', 'co_lnotab', 'co_name', 'co_names', 'co_nlocals', 'co_stacksize', 'co_varnames']
>>> dis.disassemble(x.__code__)
3 0 LOAD_FAST 0 (a)
3 LOAD_CONST 1 (1)
6 INPLACE_ADD
7 STORE_FAST 0 (a)
4 10 LOAD_FAST 1 (b)
13 LOAD_CONST 2 (2)
16 INPLACE_ADD
17 STORE_FAST 1 (b)
5 20 LOAD_GLOBAL 0 (g)
23 LOAD_CONST 3 (3)
26 INPLACE_ADD
27 STORE_GLOBAL 0 (g)
6 30 LOAD_FAST 0 (a)
33 LOAD_FAST 1 (b)
36 BINARY_ADD
37 LOAD_GLOBAL 0 (g)
40 BINARY_ADD
41 RETURN_VALUE
>>> dis.dis(x)
3 0 LOAD_FAST 0 (a)
3 LOAD_CONST 1 (1)
6 INPLACE_ADD
7 STORE_FAST 0 (a)
4 10 LOAD_FAST 1 (b)
13 LOAD_CONST 2 (2)
16 INPLACE_ADD
17 STORE_FAST 1 (b)
5 20 LOAD_GLOBAL 0 (g)
23 LOAD_CONST 3 (3)
26 INPLACE_ADD
27 STORE_GLOBAL 0 (g)
6 30 LOAD_FAST 0 (a)
33 LOAD_FAST 1 (b)
36 BINARY_ADD
37 LOAD_GLOBAL 0 (g)
40 BINARY_ADD
41 RETURN_VALUE
>>> code = compile('r = x(4, 5);print(r)', '<raw string>', 'exec')
>>> exec(code)
18
>>> eval(code)
21
>>> dir(code)
['__class__', '__cmp__', '__delattr__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__gt__', '__hash__', '__init__', '__le__', '__lt__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', 'co_argcount', 'co_cellvars', 'co_code', 'co_consts', 'co_filename', 'co_firstlineno', 'co_flags', 'co_freevars', 'co_lnotab', 'co_name', 'co_names', 'co_nlocals', 'co_stacksize', 'co_varnames']
>>> dis.disassemble(code)
1 0 LOAD_NAME 0 (x)
3 LOAD_CONST 0 (4)
6 LOAD_CONST 1 (5)
9 CALL_FUNCTION 2
12 STORE_NAME 1 (r)
15 LOAD_NAME 1 (r)
18 PRINT_ITEM
19 PRINT_NEWLINE
20 LOAD_CONST 2 (None)
23 RETURN_VALUE
>>> dis.dis(code)
1 0 LOAD_NAME 0 (x)
3 LOAD_CONST 0 (4)
6 LOAD_CONST 1 (5)
9 CALL_FUNCTION 2
12 STORE_NAME 1 (r)
15 LOAD_NAME 1 (r)
18 PRINT_ITEM
19 PRINT_NEWLINE
20 LOAD_CONST 2 (None)
23 RETURN_VALUE
>>>
参考资料
An introduction to Python bytecode
https://opensource.com/article/18/4/introduction-python-bytecode
Types and Objects in Python
http://www.informit.com/articles/article.aspx?p=453682&seqNum=5
.pyc file format of Python: format specification
http://formats.kaitai.io/python_pyc_27/index.html
The structure of .pyc files
https://nedbatchelder.com/blog/200804/the_structure_of_pyc_files.html
A Python Interpreter Written in Python
http://www.aosabook.org/en/500L/a-python-interpreter-written-in-python.html
Computed goto for efficient dispatch tables
https://eli.thegreenplace.net/2012/07/12/computed-goto-for-efficient-dispatch-tables
A cross-version Python bytecode decompiler
https://github.com/rocky/python-uncompyle6/
The standard type hierarchy - Internal types
https://docs.python.org/2.7/reference/datamodel.html#the-standard-type-hierarchy
marshal - Internal Python object serialization
https://docs.python.org/2.7/library/marshal.html
最后修改于 2019-09-02