运行驱动
librbd 是一个将 block io ([off, len])转换成 rados object io ([oid, off, len])的中间层。为了支持高性能 io 处理,其内部维护了一个 io 队列,一个异步回调队列,以及对这两个队列中的请求进行处理的线程池,如下图所示。
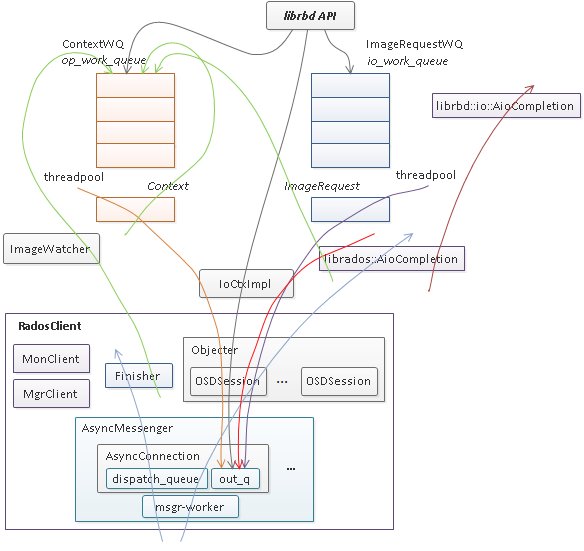
librbd 是一个 API 接口库,其提供了针对 image 的数据 io 和管理操作两种访问接口,其中数据 io 请求入 io_work_queue,然后由线程池中的线程将 io 请求以 object 粒度切分并分别调用 rados 层的 aio 接口(IoCtxImpl)下发,当所有的 object 请求完成时,调用 librbd io 回调(librbd::io::AioCompletion)完成用户层的数据 io。而对 image 的管理操作通常需要涉及单个或多个对象的多次访问以及对内部状态的多次更新,其第一次访问将从用户线程调用至 rados 层 aio 接口或更新状态后入 op_work_queue 队列进行异步调用,当 rados aio 层回调或 Context 完成时再根据实现逻辑调用新的 rados aio 或构造 Context 回调,如此反复,最后调用应用层的回调完成管理操作请求。
此外为了支持多客户端共享访问 image,librbd 提供了构建于 rados watch/notify 之上的通知、远程执行以及 exclusive lock 分布式锁机制。每个 librbd 客户端在打开 image 时(以非只读方式打开)都会 watch image 的 header 对象,从远程发往本地客户端的通知消息或者内部的 watch 错误消息会通过 RadosClient 的 Finisher 线程入 op_work_queue 队列进行异步处理。
组成元素
image 主要由 rbd_header 元数据 rados 对象及 rbd_data 数据 rados 对象组成,随着特性的增加会增加其它一些元数据对象,但 librbd 内部的运行机制并不会有大的变化,一切都以异步 io、事件(请求)驱动为基础。
创建删除
创建、删除以及克隆操作,实际上是 image 之外的一个操作,即对 image 的数据 io 和管理 op 而言,这些操作是从上帝视角进行的,当上层应用调用相应的 api 接口时,librbd 内部会创建临时的 ContextWQ 队列(实际上都是 journaling 特性相关的处理需要),然后依靠 rados 的 aio 回调和 ContextWQ 回调完成内部的处理并最终调用用户的回调完成整个操作。
打开关闭
主要对应于 ImageCtx::state 成员变量。
librbd::ImageState 内部维护了一个状态机,用于处理 OPEN, CLOSE, REFRESH, SET_SNAP, LOCK 等 5 个请求(action)。
状态机内部维护了 UNINITIALIZED, OPEN, CLOSED 等 3 个稳定状态,以及 OPENING, CLOSING, REFRESHING, SETTING_SNAP, PREPARING_LOCK 等 5 个中间状态。状态机对于请求的处理是顺序的,所有的请求都 push back 到 ImageState::m_actions_contexts 链表,如果请求有重复则先合并(但 LOCK 请求永远都不会被合并,参考 ImageState::append_context),当处于稳态时,请求会立即得到执行(参考 ImageState::execute_action_unlock),而处于中间状态时(即有请求正在处理),请求将在在之前的请求完成后再得到处理(参考 ImageState::complete_action_unlock)。
OPEN, CLOSE, REFRESH, SET_SNAP 等 4 个请求的内部处理逻辑类似,简单点说就是经过 rados aio 及 ImageCtx::op_work_queue 异步驱动状态机从中间状态至最终稳态的变化过程,但 LOCK 请求非常特殊,它会将状态机的状态置为 PREPARING_LOCK 这一中间状态(参考 ImageState::send_prepare_lock_unlock),即禁止状态机处理新的请求(注意前面提到的新请求的处理需要等待前面的请求完成),或者说所有的新请求都阻塞在 ImageState::m_actions_contexts 链表中,解除这种状态需要显式的调用 ImageState::handle_prepare_lock_complete,解除之后状态机将处于 OPEN 状态并开始处理链表中阻塞的请求。
具体看一下在哪些地方会阻塞状态机变迁(即调用 ImageState::prepare_lock):
PreAcquireRequest::send_prepare_lock
PreReleaseRequest::send_prepare_lock
EnableFeaturesRequest::send_prepare_lock
DisableFeaturesRequest::send_prepare_lock
在哪些地方会解除阻塞状态:
PostAcquireRequest::apply/PostAcquireRequest::~PostAcquireRequest
PreReleaseRequest::~PreReleaseRequest
ExclusiveLock::post_acquire_lock_handler
EnableFeaturesRequest::handle_finish
DisableFeaturesRequest::handle_finish
显然在处理分布式锁以及设置 image features 过程中需要通过这种阻塞机制禁止 image 状态发生根本的变化。
数据 io
主要对应于 ImageCtx::io_work_queue 成员变量。
librbd::io::ImageRequestWQ 派生自 ThreadPool::PointerWQ<ImageRequest>(<= Luminous) / ThreadPool::PointerWQ<ImageDispatchSpec>(>= Mimic)。
librbd 支持两种类型的 aio,一种是普通的 aio,一种是非阻塞 aio。前者的行为相对简单,直接在用户线程的上下文进行 io 处理,而后者将用户的 io 直接入 io_work_queue 队列,然后 io 由队列的工作线程出队并在工作线程上下文进行后续的处理。这两种 aio 的行为由配置参数 rbd_non_blocking_aio 决定,默认为 true,因此默认为非阻塞 aio,但需要注意的是,即使默认不是非阻塞 aio,在某些场景下 aio 仍然会需要入 io_work_queue 队列,总结如下。
read
ImageRequestWQ::writes_blocked()为 true,即已调用ImageRequestWQ::block_writes,当前已禁止 write io 下发至 rados 层;ImageRequestWQ::writes_empty()为 false,即前面已经有 write io 入了io_work_queue队列;ImageRequestWQ::require_lock_on_read()为 true,这里的 lock 是指 exclusive lock,表示当前还未拿到,在启用 exclusive lock 特性的前提下,一旦开启克隆 COR (copy on read) 或者启用 journaling 特性,处理 read io 也要求拿锁;
write
ImageRequestWQ::writes_blocked()为 true,即已调用ImageRequestWQ::block_writes,当前已禁止 write io 下发至 rados 层;
对于 write 而言,并没有类似 ImageRequestWQ::require_lock_on_write 的接口,这是因为一旦启用 exclusive lock 特性,在初始化 exclusive lock 时会调用 ImageRequestWQ::block_writes(参考 ExclusiveLock::init),直至拿到锁(参考 ExclusiveLock::handle_post_acquired_lock),因此增加 ImageRequestWQ::require_lock_on_write 接口并没有必要。
需要注意的是,ImageRequestWQ::block_writes 并不只是简单的设置禁止标志,还需要 flush 已下发的 rados io,即等待所有已下发的 rados io 结束才返回。
从上面对 read、write 的分析,似乎 ImageRequestWQ::writes_blocked 改成 ImageRequestWQ::io_blocked 似乎更合理,但实际上这里并没有真的禁止 read io 下发至 rados 层,只是让 read io 先入 io_work_queue 队列。
管理 op
主要对应于 ImageCtx::operations 成员变量。
exclusive lock
主要对应于 ImageCtx::exclusive_lock 成员变量。
exclusive lock 主要用于协调多个 librbd 客户端(可以是多进程,也可以是单个进程内的多线程,只要是对同一个 image 通过多个 ImageCtx 访问即认为是多客户端)之间的访问。
ExclusiveLock 是 ManagedLock 的派生实现(另一个派生的子类是 rbd::mirror::LeaderWatcher::LeaderLock),ManagedLock 内部也是一个状态机,用于处理 TRY_LOCK, ACQUIRE_LOCK, REACQUIRE_LOCK, RELEASE_LOCK, SHUT_DOWN 等 5 个请求(action)。
状态机内部维护了 UNLOCKED, LOCKED, SHUTDOWN, UNINITIALIZED 等 4 个稳定状态,以及 INITIALIZING, WAITING_FOR_REGISTER, ACQUIRING, REACQUIRING, WAITING_FOR_LOCK, POST_ACQUIRING, PRE_RELEASING, RELEASING, PRE_SHUTING_DOWN, SHUTING_DOWN 等 10 个中间状态。与 ImageState 状态机类似,状态机对于请求的处理是顺序的(REACQUIRE_LOCK 有所例外),所有的请求都 push back 到 ManagedLock::m_actions_contexts 链表,如果请求有重复则合并,参考 ManagedLock::append_context),当处于稳态时,请求会立即得到执行(参考 ManagedLock::execute_action),而处于中间状态时(即有请求正在处理),请求将在之前的请求完成后再得到处理(参考 ManagedLock::complete_active_action)。
WAITING_FOR_LOCK 这个状态只由 ExclusiveLock::post_acquire_lock_handler 设置,当处理 ACQUIRE_LOCK 请求时,如果返回了 -EBUSY / -EAGAIN 错误,则将通过 ImageWatcher 去请求当前锁的拥有者释放锁(ImageWatcher::handle_request_lock),此时状态机的运行将中断(ManagedLock::handle_post_acquire_lock 中的 r == -ECANCELED 分支),直至 ImageWatcher::handle_request_lock 调用 ExclusiveLock::handle_peer_notification 再次驱动状态机运行。
REACQUIRE_LOCK 请求只由 Watcher::handle_rewatch_callback 调用 ManagedLock::reacquire_lock 产生,并不会被暴露到 api 层供用户主动调用。在处理 watch 出错时,如果 rewatch 成功,或者客户端已被加入黑名单或 watch 的对象被删除,Watcher::handle_rewatch_callback 将被调用(参考 Watcher::handle_rewatch),并最终调用 ManagedLock::reacquire_lock 更新状态机,根据当前状态机所处的状态 ManagedLock::reacquire_lock 有如下的处理:
-
如果当前处于
WAITING_FOR_REGISTER状态,说明之前的TRY_LOCK或者ACQUIRE_LOCK请求处理期间由于 watch 错误导致状态机运行中断(参考ManagedLock::send_acquire_lock),此时REACQUIRE_LOCK请求类似于一个 dummy 事件用于驱动状态机完成前面未完成的TRY_LOCK或ACQUIRE_LOCK请求,即此时REACQUIRE_LOCK请求并不会加入到请求处理链表,而是直接执行前面终止的TRY_LOCK或ACQUIRE_LOCK请求(参考ManagedLock::reacquire_lock); -
如果当前处于
LOCKED,ACQUIRING,POST_ACQUIRING,WAITING_FOR_LOCK状态,则将REACQUIRE_LOCK加入到请求处理链表并进行处理,显然除LOCKED之外的 3 种状态都是中间状态,因此需要等待当前未完成的请求完成之后REACQUIRE_LOCK才能得到处理。如果处理REACQUIRE_LOCK请求时状态机不处于LOCKED状态,此时 watcher 的状态并不影响状态机,因此忽略并结束处理,如果处于LOCKED状态,则需要重新评估 watcher 状态的变化对状态机的影响,此时根据 watcher 的状态分如下几种情况:
- watch 出错后,rewatch 同样失败,说明 watcher 已加入黑名单或 watcher 的 object 已被删除(参考
Watcher::handle_rewatch),则加入RELEASE_LOCK以及ACQUIRE_LOCK请求到请求处理链表待处理(ManagedLock::release_acquire_lock)。注意由于当前状态机处于REAQUIRING中间状态,因此需要先完成REACQUIRE_LOCK请求并临时设置状态到LOCKED状态(参考ManagedLock::send_reacquire_lock); - rewatch 成功,且 lock 的 cookie 没有发生变化,说明当前 watcher 仍然是锁的持有者,不需要再做别的处理;
- rewatch 成功,但 lock 的 cookie 发生了变化,尝试去服务端更新 cookie(
ReacquireRequest::set_cookie),如果失败则回到与第一步一样的处理;
- 如果当前处于其它状态,说明此时 watcher 的状态并不影响状态机,忽略并结束处理;
注意 watch 机制是异步的,watch 与 OSD 的联系可能会因为网络中断、PG recovery / scrub (参考 osd/Watch.cc/HandleWatchTimeout)、watch 的 object 被删除等原因而中断, 因此 notify 也可能因此而超时(rados 的 watch/notify 机制将在另外的文档中进行介绍),在多个客户端争抢锁的过程中如果因为 notify 不成功,会直接将对端加入黑名单而阻止对端的 io 继续下发(黑名单对于主动获取、释放 exclusive lock 的业务,如 tcmu-runner iSCSI 的 AP 模式是必须的);
image watcher
主要对应于 ImageCtx::image_watcher 成员变量。
最后修改于 2019-02-19